Nicar2015 in Atlanta was my first conference as a Knight-Mozilla fellow and it was a fantastic experience. More than 1,000 people from the journalism & desgin & technology fields gather for an intensive stint of 4-5 days with hands-on sessions, panels and demos on tools to innovate in Computer Assisted Journalism.
One of the first things that you realize once you get there is that you are going to have a feeling of missing out no matter how hard you try. There are over 10 simultaneous sessions and unless you can clone yourself (tried that but didn't work...) you need to carefully choose the sessions that you think you can take more profit from.


Let me go through some of the sessions that I have enjoyed the most, but before that, I will point you to a really useful resource here curated by @MacDiva for you to dive in the session slides that are more aligned with your field of interest.
I can divide the sessions that had more impact on me in two subgroups: technical and management oriented. Here are my favorites:
Management oriented sessions
Do it once and only once

Speakers: Derek Willis & David Eaves
Derek and David warned us about the time wasting perils of data processing without automation and audit trails.
One of the highlights of the talk to me was finding out about Ben Balter change agent: A Git-backed key-value store, for tracking changes to documents and other files over time as defined by Ben in the repo.
I always thought that version control will be applied to other industries outside technology soon, and that is going to be a changemaker in that industry.
Slides: Derek Slides & David Slides
Processes, standards and documentation for data-driven projects
Speakers: Christopher Groskopf & Paul Overberg
In this session Paul and Christopher walked us through the importance of creating team standards, project vocabularies and consistent procedures to produce high quality projects in a sustainable way. This is specially crucial when working under a deadline, something that happens naturally in newsrooms.
In particular, I found Christopher's part full of wisdom. Coming from someone that has worked in newsrooms and remotely for a while and that has taken the time to share his experience in this invaluable tips.
Technical sessions
From text to pictures
Speakers: Nicholas Diakopoulos
On thursday I had a really good start with a session on how to handle and interpret big amounts of text through visualization by Nicholas Diakopoulos.
Nicholas explored different approaches on analizing texts and visualing the content or even the structure to get an insight of what is hidden in that pile of data, after all text is data right?
But Nicholas pointed out that text is data but with a particular behavior, the order in which words appear is important to the meaning of a sentence and you need to take that into account.
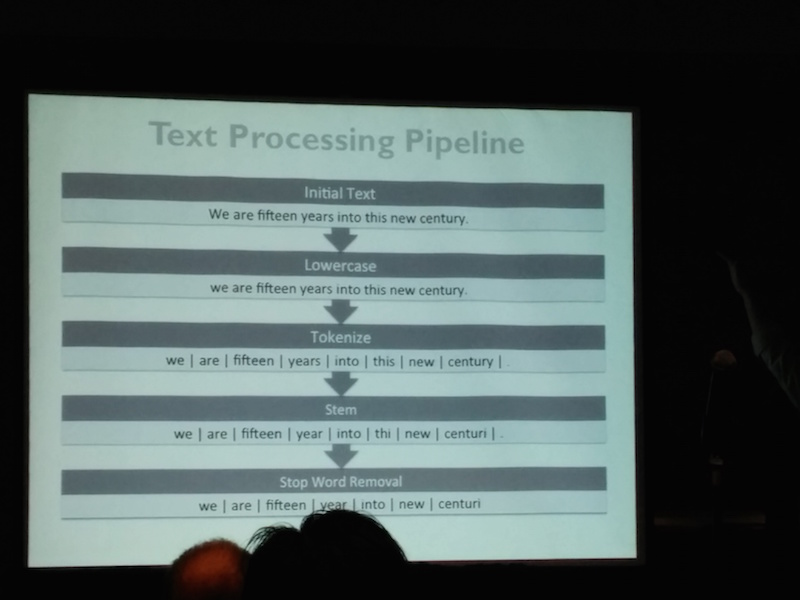
He also talked about the necessary text processing pipeline in order to get a useful analysis
- Initial text
- Lowercase
- Tokenize
- Stem
- Stop Word Removal.
Slides: Nicholas Slides
Plot.ly

Speakers: Matthew Sundquist
Until NICAR I had not heard about plot.ly (yeah I know...shame on me!!) and I think that it has a lot of potential in the data journalism field and ranging from journalists that want to create graphs without coding to developers through their API.
It generates D3.js visualizations under the hood but it exposes many ways to perform an integration with the platform.
To find out more just check their tutorials and API documentation
Using machine learning to deal with dirty data: a Dedupe demonstration

Speakers: Jeff Ernsthausen, Derek Eder, Eric van Zanten & Forest Gregg
If I had to pick my favorite session from this year's conference I would have to choose the demo on a tool developed by datamade called Dedupe.
It is a machine learning based python library for accurate and scalable data deduplication and entity-resolution. I have fought many times with trying to combine different datasets that do not have a clear identifier to join by. OpenRefine can help with small datasets but the process of clustering is not repeatable and even more important it is not scalable.
Having a machine learning process for that kind of task is probably the best way to go. I got so inspired by that demo that I think a big part of my fellowship is going to be focused on machine learning and how to apply it to journalistic problems.

As a starter I am going to use dedupe to try to match two different datasets for the upcoming argentinian elections, in next posts I will tell you how it went and what have I learned in the process.
Technical tip of the day
Let's dig a little bit deeper on how to install Numpy with parallel processing support on a Mac OS X (tested on 10.9 and 10.10) you can read more about the convoluted issue here. Since it took me a while to get things working so I thought maybe sharing my pains can help someone in the future.
I will walk you through the installation process that has worked for me, if you think it can be improved don't hesitate to contact me.
-
If you have not installed homebrew, the first step is to do so:
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
-
Set up some compilation flags on your environment of choice
export CFLAGS=-Qunused-arguments export CPPFLAGS=-Qunused-arguments
-
Brew tap the homebrew python repo
$ brew tap homebrew/python -
Install Numpy with OpenBlas support
$ brew install numpy --with-openblas -
Check if Numpy is linked against OpenBlas
>>> import numpy as np >>> np.__config__.show()
-
You should see an output like this
lapack_opt_info: libraries = ['openblas', 'openblas'] library_dirs = ['/usr/local/opt/openblas/lib'] language = f77 blas_opt_info: libraries = ['openblas', 'openblas'] library_dirs = ['/usr/local/opt/openblas/lib'] language = f77 openblas_info: libraries = ['openblas', 'openblas'] library_dirs = ['/usr/local/opt/openblas/lib'] language = f77 openblas_lapack_info: libraries = ['openblas', 'openblas'] library_dirs = ['/usr/local/opt/openblas/lib'] language = f77 blas_mkl_info: NOT AVAILABLE
-
Now you can continue with the normal installation process for dedupe, just remember to include system packages if you are going to use a virtualenv so that the compiled Numpy with OpenBlas support will be used inside the virtual environment
$ virtualenv venv --system-site-packages
Wrap up
This year's NICAR conference in Atlanta was overall a great experience, It has guided me towards machine learning as a focus for my fellowship year. I think this technique will become more and more adopted by newsrooms in the following years.
I have met many people with my same interests (is always good not to feel alone... ;-)). I also had the opportunity to get to chat more with the 2015 knight-mozilla fellows cohort and also spend sometime with other fellows from past years.
I would recommend anyone interested in the data journalism field to at least attend once to this conference organized by Investigative Reporters & Editors you will not regret it.
Comments
comments powered by Disqus